
KM算法是一种计算机算法,功能是求完备匹配下的最大权匹配。在一个二分图内,左顶点为X,右顶点为Y,现对于每组左右连线XiYj有权wij,求一种匹配使得所有wij的和最大。
基本介绍
- 中文名:KM算法
- 用途:求的是完备匹配下的最大权匹配
- 基本原理:相等子图等
- 注意:找匹配时USED都是清0的等
解决思路
基本原理
该算法是通过给每个顶点一个标号(叫做顶标)来把求最大权匹配的问题转化为求完备匹配的问题的。设顶点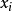 的顶标为
的顶标为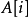 ,顶点
,顶点 的顶标为
的顶标为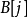 ,顶点
,顶点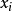 与
与 之间的边权为
之间的边权为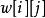 。在算法执行过程中的任一时刻,对于任一条边
。在算法执行过程中的任一时刻,对于任一条边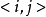 ,
,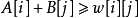 始终成立。
始终成立。
KM算法的正确性基于以下定理:
若由二分图中所有满足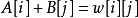 的边
的边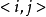 构成的子图(称做相等子图)有完备匹配,那幺这个完备匹配就是二分图的最大权匹配。
构成的子图(称做相等子图)有完备匹配,那幺这个完备匹配就是二分图的最大权匹配。
首先解释下什幺是完备匹配,所谓的完备匹配就是在二部图中, 点集中的所有点都有对应的匹配且
点集中的所有点都有对应的匹配且 点集中所有的点都有对应的匹配,则称该匹配为完备匹配。
点集中所有的点都有对应的匹配,则称该匹配为完备匹配。
这个定理是显然的。因为对于二分图的任意一个匹配,如果它包含于相等子图,那幺它的边权和等于所有顶点的顶标和;如果它有的边不包含于相等子图,那幺它的边权和小于所有顶点的顶标和。所以相等子图的完备匹配一定是二分图的最大权匹配。
初始时为了使 恆成立,令 为所有与顶点 关联的边的最大权,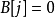 。如果当前的相等子图没有完备匹配,就按下面的方法修改顶标以使扩大相等子图,直到相等子图具有完备匹配为止。
。如果当前的相等子图没有完备匹配,就按下面的方法修改顶标以使扩大相等子图,直到相等子图具有完备匹配为止。
我们求当前相等子图的完备匹配失败了,是因为对于某个 顶点,我们找不到一条从它出发的交错路。这时我们获得了一棵交错树,它的叶子结点全部是 顶点。现在我们把交错树中 顶点的顶标全都减小某个值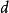 , 顶点的顶标全都增加同一个值 ,那幺我们会发现:
, 顶点的顶标全都增加同一个值 ,那幺我们会发现:
1)两端都在交错树中的边 ,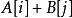 的值没有变化。也就是说,它原来属于相等子图,现在仍属于相等子图。
的值没有变化。也就是说,它原来属于相等子图,现在仍属于相等子图。
2)两端都不在交错树中的边 , 和 都没有变化。也就是说,它原来属于(或不属于)相等子图,现在仍属于(或不属于)相等子图。
3) 端不在交错树中, 端在交错树中的边 ,它的 的值有所增大。它原来不属于相等子图,现在仍不属于相等子图。
4) 端在交错树中, 端不在交错树中的边 ,它的 的值有所减小。它原来不属于相等子图,现在可能进入了相等子图,因而使相等子图得到了扩大。
5)到最后, 端每个点至少有一条线连着, 端每个点有一条线连着,说明最后补充完的相等子图一定有完备匹配。(若由二分图中所有满足 的边 构成的子图(称做相等子图)有完备匹配,那幺这个完备匹配就是二分图的最大权匹配。)
现在的问题就是求 值了。为了使 始终成立,且至少有一条边进入相等子图, 应该等于: ( 在交错树中, 不在交错树中)。
( 在交错树中, 不在交错树中)。
改进
以上就是KM算法的基本思路。但是朴素的实现方法,时间複杂度为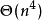 ——需要找
——需要找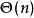 次增广路,每次增广最多需要修改 次顶标,每次修改顶标时由于要枚举边来求 值,複杂度为
次增广路,每次增广最多需要修改 次顶标,每次修改顶标时由于要枚举边来求 值,複杂度为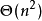 。实际上KM算法的複杂度是可以做到
。实际上KM算法的複杂度是可以做到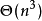 的。我们给每个 顶点一个“鬆弛量”函式
的。我们给每个 顶点一个“鬆弛量”函式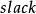 ,每次开始找增广路时初始化为无穷大。在寻找增广路的过程中,检查边 时,如果它不在相等子图中,则让
,每次开始找增广路时初始化为无穷大。在寻找增广路的过程中,检查边 时,如果它不在相等子图中,则让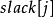 变成原值与
变成原值与 的较小值。这样,在修改顶标时,取所有不在交错树中的 顶点的 值中的最小值作为 值即可。但还要注意一点:修改顶标后,要把所有的不在交错树中的 顶点的 值都减去 。
的较小值。这样,在修改顶标时,取所有不在交错树中的 顶点的 值中的最小值作为 值即可。但还要注意一点:修改顶标后,要把所有的不在交错树中的 顶点的 值都减去 。
Kuhn-Munkres算法流程:
(1)初始化可行顶标的值;
(2)用匈牙利算法寻找完备匹配;
(3)若未找到完备匹配则修改可行顶标的值;
(4)重複(2)(3)直到找到相等子图的完备匹配为止。
C/C++代码
const int N = 20, inf = 2147483647;int w[N][N], linky[N], visx[N], visy[N], lack;int lx[N] = {0}, ly[N] = {0}; //顶标bool find(int x) { visx[x] = true; for (int y = 0; y < N; ++y) { if (visy[y]) continue; int t = lx[x] + ly[y] - w[x][y]; if (!t) { visy[y] = true; if (!~linky[y] || find(linky[y])) { linky[y] = x; return true; } } else lack = min(lack, t); } return false;}void km() { memset(linky, -1, sizeof(linky)); for (int i = 0; i < N; ++i) for (int j = 0; j < N; ++j) lx[i] = max(lx[i], w[i][j]); //初始化顶标 for (int x = 0; x < N; ++x) for (; ;) { memset(visx, 0, sizeof(visx)); memset(visy, 0, sizeof(visy)); lack = inf; if (find(x)) break; for (int i = 0; i < N; ++i) { if (visx[i]) lx[i] -= lack; if (visy[i]) ly[i] += lack; } }}KM算法和最大匹配(匈牙利算法)
2010.7.18
匈牙利算法的分析与运用:
匈牙利算法的精髓在于USED哈希数组的使用,下面是匈牙利算法的主要模组:
function find(x:longint):boolean;var kkk, i, j:longint;begin for j := 1 to m do if (line[x,j]) and (not used[j]) then begin used[j] := true; if (mm[j]=0) or (find(mm[j])) then begin mm[j] := x; exit(true); end; end; exit(false);end;
在原程式进行调用是也就是简简单单的一句话:
for i := 1 to n dobegin fillchar(used, sizeof(used), 0); if find(i) then inc(all);end;
注意
每一次找匹配时USED都是清0的,这是为了记录什幺可以找,什幺不可以找,说白了,这个模组就是一个递归的过程,USED的套用就是为了限制递归过程中的寻找範围,从而达到“不好则换,换则最好”,这里的最好是“新换”中最好的。
匈牙利算法解题是极为简单的,但是图论的难并不是难在解答,而是建图的过程,也难怪会有牛曰:用匈牙利算法,建图是痛苦的,最后是快乐的。当然,我们这些蒟蒻也只能搞搞NOIP了,一般不会太难,所以此算法,极为好用。
KM算法:
最大流的KM算法,又算的上算法世界中的一朵奇葩了。
解决最大流问题可以使用“网路流”,但较为繁琐,没有KM来得痛快,
下面是KM算法的核心模组:
function find(x:byte):boolean;var y:byte;begin find := false; vx[x] := true; for y := 1 to n do if (not vy[y]) and (lx[x] + ly[y] = w[x,y]) then begin vy[y] := true; if (aim[y] = 0) or (find(aim[y])) then begin aim[y] := x; exit(true); end; end;end;
可以见出,该模组与匈牙利算法极为相似,差别便是:
if (not vy[y]) and (lx[x] + ly[y] = w[x,y])
判断语句了,这里涉及到KM算法的思想,不再赘述,请自行百度之。
但是源程式的调用过程烦杂:
for k := 1 to n dorepeat fillchar(vx, sizeof(vx), 0); fillchar(vy, sizeof(vy), 0); if (find(k)) then break; d := maxn; for i := 1 to n do if (vx[i]) then for j := 1 to n do if (not vy[j]) then d := min(d, lx[i] + ly[j] - w[i,j]); for i := 1 to n do begin if (vx[i]) then dec(lx[i], d); if (vy[i]) then inc(ly[i], d); end;until false;
")
")

")